
Bo Dai 戴勃
Scientist
Shanghai AI Laboratory
Email: doubledaibo [at] gmail [dot] com
Bio
Dr. Bo Dai is a scientist with Shanghai AI Laboratory, leading a research group on Content Generation and Digitization. Prior to joining Shanghai AI Lab, he worked as a Research Assistant Professor with S-Lab, Nanyang Technological University, Singapore. He was a Postdoctoral Research Fellow in Multimedia Laboratory (MMLab), CUHK. He received his Ph.D. (2014-2018) from Multimedia Laboratory (MMLab) at CUHK, advised by Prof.Dahua Lin. He obtained his B.Eng. (2010-2014) from ACM class of SJTU.
I'm looking for researchers/interns/phds/post-docs. Drop me an email if you are interested.
Recent Research Highlights
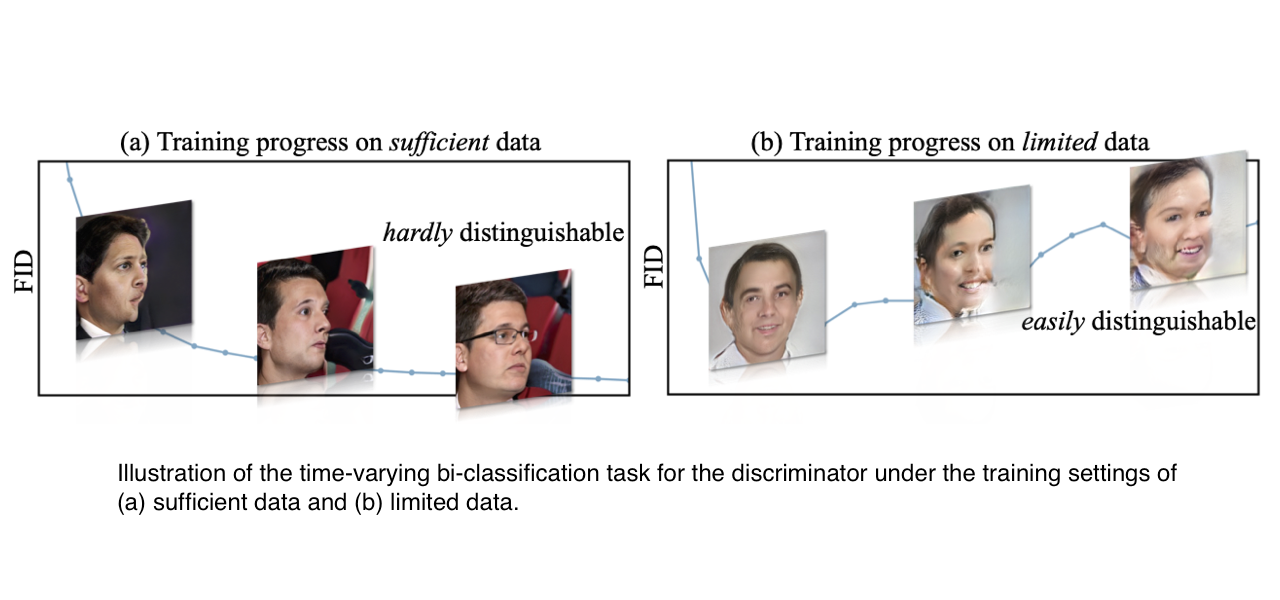
DynamicD
In DynamicD, we argue that the training-time synthesis distribution of GANs keeps varying, and thus effects the bi-classification task for the discriminator, which further leads to various notorious issues in training GANs. We thus propose an on-the-fly adjustment on the discriminator's capacity that can better accommodate such a time-varying task. The proposed training strategy, termed as DynamicD, is general and effective across different synthesis tasks and dataset scales, without incurring any additional computation cost or training objectives.

MaskCLIP
In MaskCLIP, we present the pioneering study that examines the intrinsic potential of CLIP for pixel-level dense prediction, specifically in semantic segmentation. With minimal additional designs, MaskCLIP is able to improve SOTA transductive zero-shot semantic segmentation methods significantly (from 35.6/20.7/30.3 to 86.1/66.7/54.7). Our study also reveals the robustness of MaskCLIP and its capability in discriminating fine-grained objects and novel concepts (e.g. Joker and Batman).
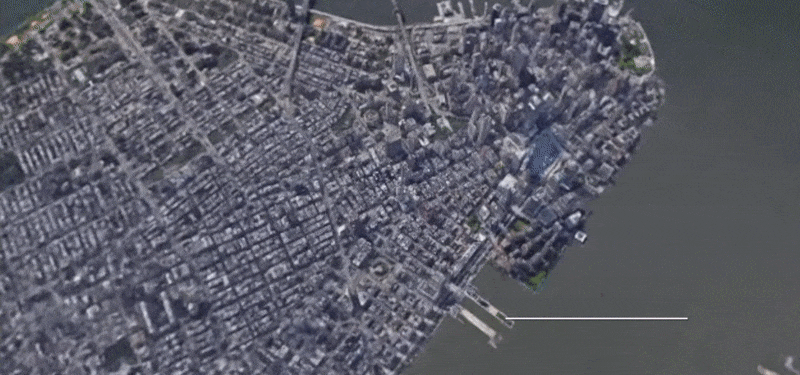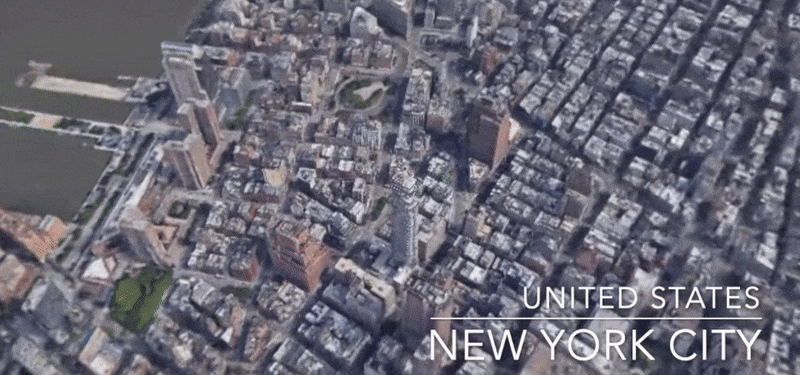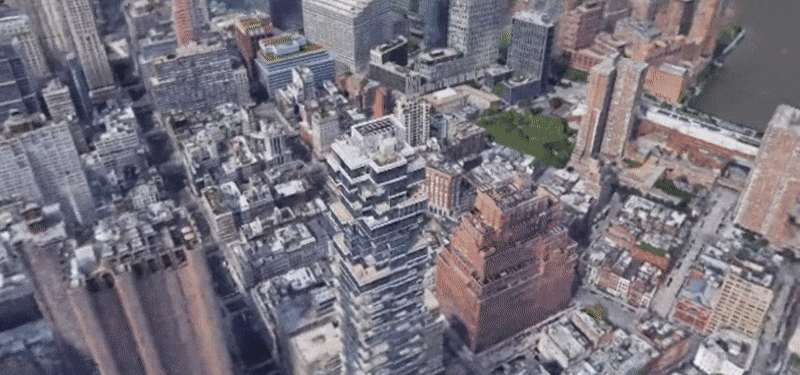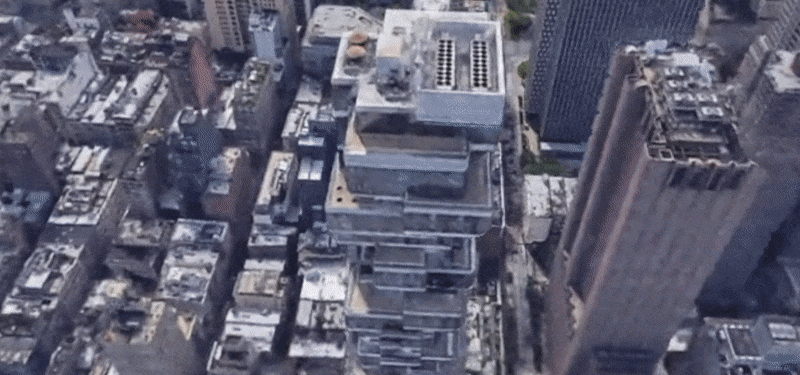
BungeeNeRF
In BungeeNeRF, we extend NeRF to large-scale scenes whose views are observed at drastically different scales, such as city scenes, with views ranging from satellite level to ground level imagery. Such extreme scale variance poses great challenges to existing NeRF variants. BungeeNeRF follows a progressive growing paradigm to effectively activates high-frequency PE channels and successively unfolds more complex details as the training proceeds, resulting in high-quality rendering in different levels of detail.
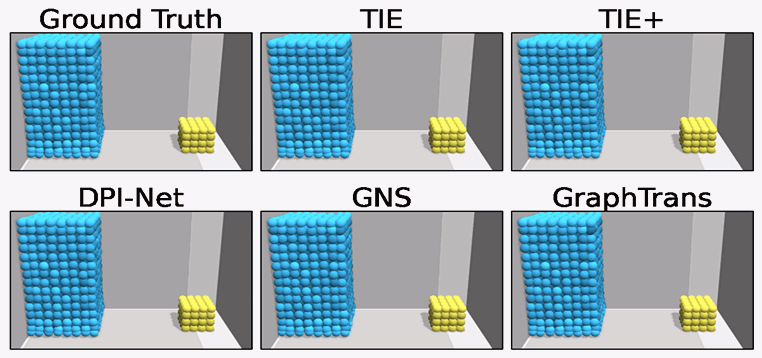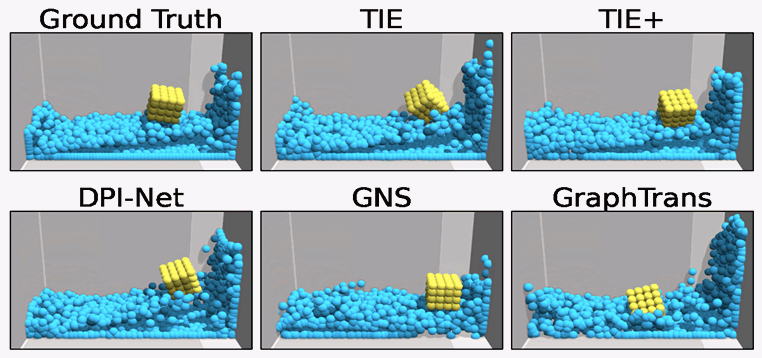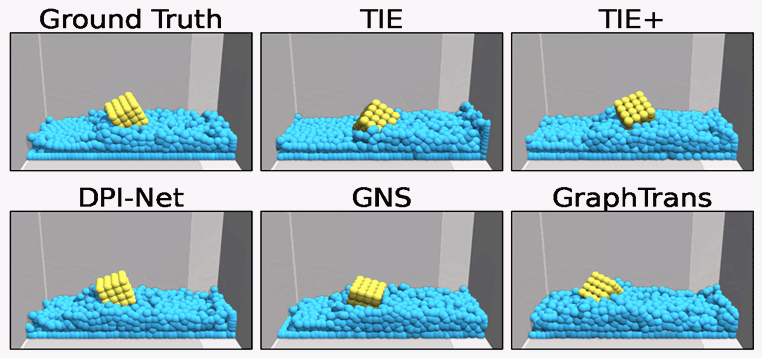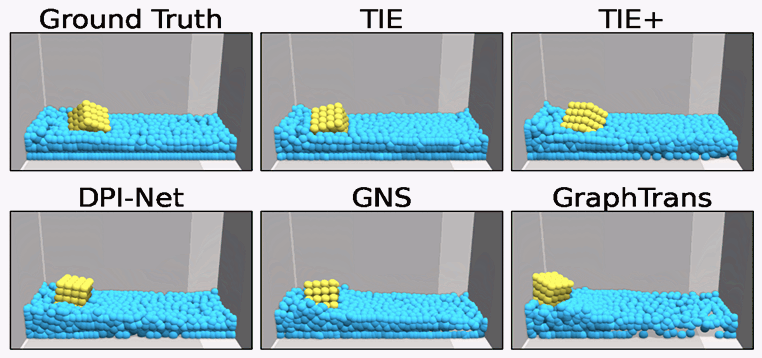
TIE
In TIE, we introduce a Transformer-based network for particle-based simulation that can capture the rich semantics of particle interactions in an edge-free manner, so that TIE is combined with the merits of GNN-based approaches without suffering from their significant computational overhead. TIE is further amended with learnable material-specific abstract particles to disentangle global material-wise semantics, which help TIE achieve superior generalization across various simulation domains.
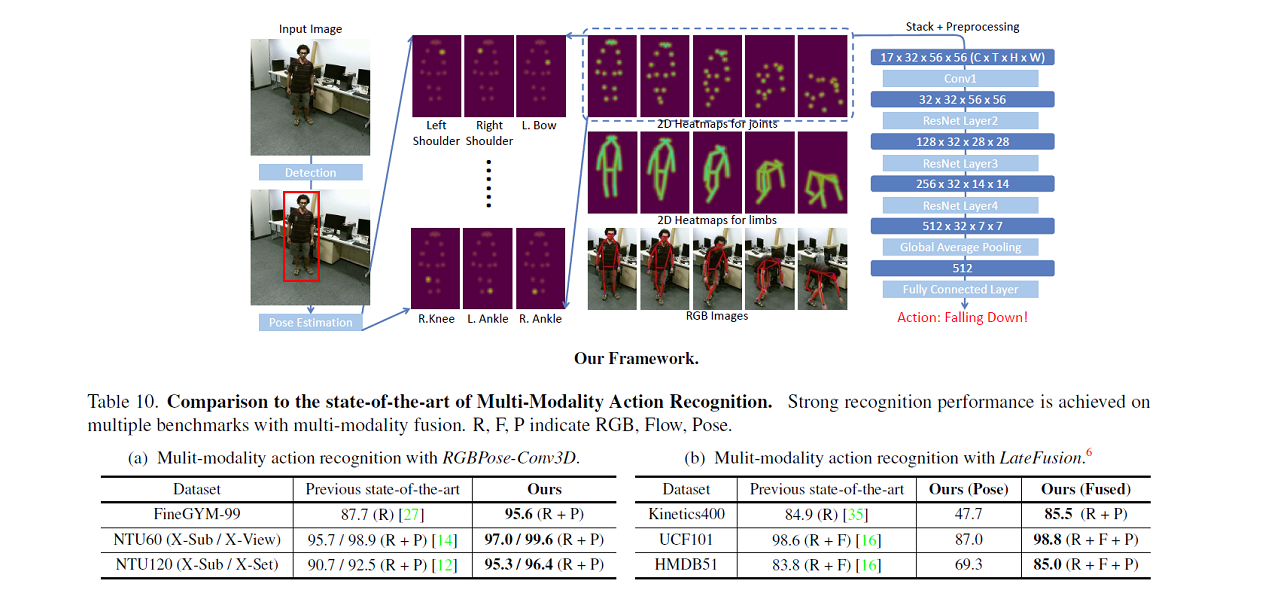
PoseConv3D
In PoseConv3D, we propose a new approach to skeleton-based action recognition that avoids the limitations of GCN-based methods in terms of robustness, interoperability, and scalability. PoseConv3D relies on CNN-based architectures as the backbone, taking a 3D heatmap volume instead of a graph sequence as the input representation of human skeletons. In this way PoseConv3D can be easily integrated with other modalities at early fusion stages, providing a great design space to boost the performance.
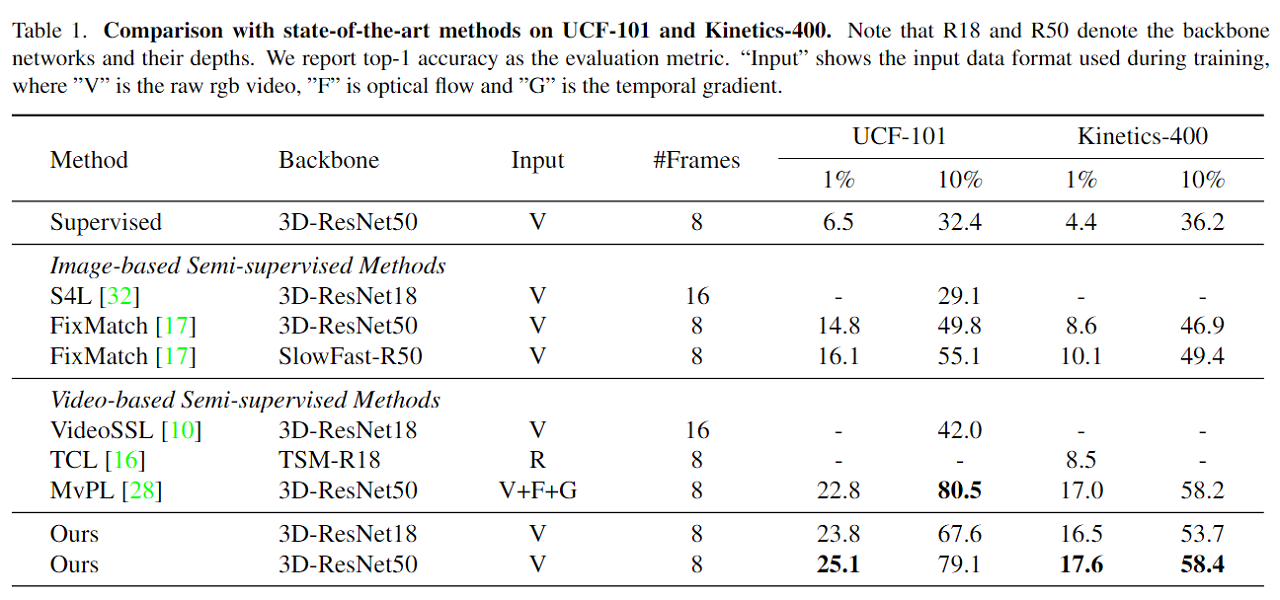
Cross-Model Pseudo-Labeling
In CMPL, we propose a more effective pseudo-labeling scheme for semi-supervised action recognition, called Cross-Model Pseudo-Labeling (CMPL). Concretely, we introduce a lightweight auxiliary network in addition to the primary backbone, and ask them to predict pseudo-labels for each other. We observe that, due to their different structural biases, these two models tend to learn complementary representations, and subsequently benefit each other by utilizing cross-model predictions as supervision.
News
- [04/2023] Group website is online.
- [02/2023] Four papers are accepted to CVPR2023.
- [09/2022] One paper is accepted to NeurIPS2022.
- [07/2022] Six papers (one oral, five posters) are accepted to ECCV 2022.
- [03/2022] Five papers (two orals, three posters) are accepted to CVPR2022.
- [01/2022] Gave a talk "Learning Shapes from Unposed 2D Images using Generative Adversarial Networks" at GAMES.
- [12/2021] Code release of GOF, ShadeGAN, APA!